It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Контент предоставлен O'Reilly Media. Весь контент подкастов, включая выпуски, графику и описания подкастов, загружается и предоставляется непосредственно O'Reilly Media или его партнером по платформе подкастов. Если вы считаете, что кто-то использует вашу работу, защищенную авторским правом, без вашего разрешения, вы можете выполнить процедуру, описанную здесь https://ru.player.fm/legal.
Похожие на O'Reilly Data Show Podcast
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
As She Rises brings together local poets and activists from throughout North America to depict the effects of climate change on their home and their people. Each episode carries the listener to a new place through a collection of voices, local recordings and soundscapes. Stories span from the Louisiana Bayou, to the tundras of Alaska to the drying bed of the Colorado River. Centering the voices of native women and women of color, As She Rises personalizes the elusive magnitude of climate cha ...
…
continue reading
Ever wondered what makes great go-to-market leaders grow, even when the going gets tough? We have, too. And we’re on a mission to uncover the magic that makes that growth happen. This is Go-to-Market Magic, the show where we talk to go-to-market leaders and visionaries about the “aha!” moments they experience and the pivotal decisions they’ve made, all in the name of growth. And we’re not just talking about revenue growth that goes up and to the right — we’ll also discuss how they improve th ...
…
continue reading
The Partnership Economy explores the power of partnerships through candid conversations and stories with industry leaders. Our hosts, David A. Yovanno, CEO and Todd Crawford, Co-founder, of impact.com, unpack the future of partnerships as a lever for scale and an opportunity to put the consumer first.
…
continue reading
Bitcoin groundbreakers share personal stories of how Bitcoin is changing lives for the better. Host Mauricio Di Bartolomeo, co-founder and CSO of Ledn, speaks with leading Bitcoin voices, entrepreneurs, and human rights advocates to hear their unique journey and practical real-world examples of how Bitcoin has made a positive impact in their lives. Brought to you by Ledn, a leading financial services company built for Bitcoin & digital assets. Ledn offers a suite of lending, saving and tradi ...
…
continue reading
Welcome to the What’s Next! Podcast. I’ve met so many brilliant people as I traveled the globe and have had some fascinating conversations that I’ve wished had been recorded so I could share them with you - this podcast was a way for me to recreate those moments and let you in on some fantastic insights. My current conversations center around one objective: what's next for companies and individuals as they look to innovate and grow. I hope these conversations inspire you as much as they have ...
…
continue reading
Tim Harford and the More or Less team try to make sense of the statistics which surround us. From BBC Radio 4
…
continue reading
How do I start an online business? How do I build a brand online? How do I get traffic and attention to my online business? The biggest question is, can I start a business online and replace my current JOB? Welcome to The Rock Your Brand podcast show where we answer ALL of these questions and a ton MORE! Scott Voelker, the host will share with you everything you need to know and help you to build a Future Proof Business that will allow you the ultimate Freedom. Scott shares tips and strategi ...
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Player FM - приложение для подкастов
Работайте офлайн с приложением Player FM !
Работайте офлайн с приложением Player FM !

))
Labeling, transforming, and structuring training data sets for machine learning
Manage episode 248276630 series 61203
Контент предоставлен O'Reilly Media. Весь контент подкастов, включая выпуски, графику и описания подкастов, загружается и предоставляется непосредственно O'Reilly Media или его партнером по платформе подкастов. Если вы считаете, что кто-то использует вашу работу, защищенную авторским правом, без вашего разрешения, вы можете выполнить процедуру, описанную здесь https://ru.player.fm/legal.
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
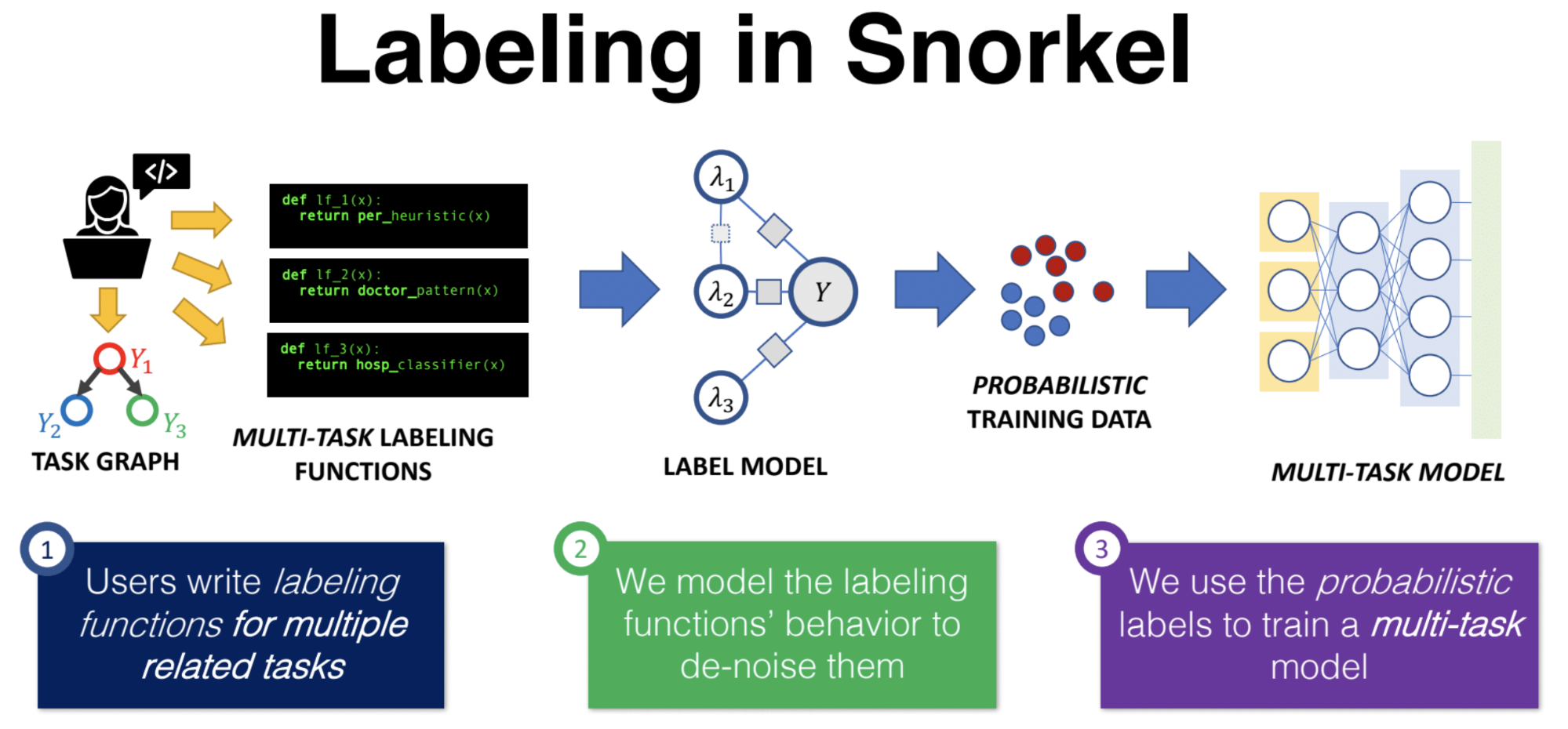
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 эпизодов
Manage episode 248276630 series 61203
Контент предоставлен O'Reilly Media. Весь контент подкастов, включая выпуски, графику и описания подкастов, загружается и предоставляется непосредственно O'Reilly Media или его партнером по платформе подкастов. Если вы считаете, что кто-то использует вашу работу, защищенную авторским правом, без вашего разрешения, вы можете выполнить процедуру, описанную здесь https://ru.player.fm/legal.
In this episode of the Data Show, I speak with Alex Ratner, project lead for Stanford’s Snorkel open source project; Ratner also recently garnered a faculty position at the University of Washington and is currently working on a company supporting and extending the Snorkel project. Snorkel is a framework for building and managing training data. Based on our survey from earlier this year, labeled data remains a key bottleneck for organizations building machine learning applications and services.
Ratner was a guest on the podcast a little over two years ago when Snorkel was a relatively new project. Since then, Snorkel has added more features, expanded into computer vision use cases, and now boasts many users, including Google, Intel, IBM, and other organizations. Along with his thesis advisor professor Chris Ré of Stanford, Ratner and his collaborators have long championed the importance of building tools aimed squarely at helping teams build and manage training data. With today’s release of Snorkel version 0.9, we are a step closer to having a framework that enables the programmatic creation of training data sets.
We had a great conversation spanning many topics, including:
- Why he and his collaborators decided to focus on “data programming” and tools for building and managing training data.
- A tour through Snorkel, including its target users and key components.
- What’s in the newly released version (v 0.9) of Snorkel.
- The number of Snorkel’s users has grown quite a bit since we last spoke, so we went through some of the common use cases for the project.
- Data lineage, AutoML, and end-to-end automation of machine learning pipelines.
- Holoclean and other projects focused on data quality and data programming.
- The need for tools that can ease the transition from raw data to derived data (e.g., entities), insights, and even knowledge.
Related resources:
- “Product management in the machine learning era”: A tutorial at the Artificial Intelligence Conference in San Jose, September 9-12, 2019.
- Chris Ré: “Software 2.0 and Snorkel”
- Alex Ratner: “Creating large training data sets quickly”
- Ihab Ilyas and Ben Lorica on “The quest for high-quality data”
- Roger Chen: “Acquiring and sharing high-quality data”
- Jeff Jonas on “Real-time entity resolution made accessible”
- “Data collection and data markets in the age of privacy and machine learning”
168 эпизодов
Все серии
×Добро пожаловать в Player FM!
Player FM сканирует Интернет в поисках высококачественных подкастов, чтобы вы могли наслаждаться ими прямо сейчас. Это лучшее приложение для подкастов, которое работает на Android, iPhone и веб-странице. Зарегистрируйтесь, чтобы синхронизировать подписки на разных устройствах.
Похожие на O'Reilly Data Show Podcast
It didn’t all change in March 2020. Not really. The UK high street has been in the throes of a gradual revolution for decades. From the rise of ecommerce, to the birth of mobile, social commerce, and a growing emphasis on experience, change has been underway for a while. In fact for many, the pandemic has acted as a wake-up call. Digital transformation was no longer a ‘nice to have’ but a matter of survival. Necessity sparked innovation and customers are enjoying more flexibility and conveni ...
…
continue reading
Custom Manufacturing Industry podcast is an entrepreneurship and motivational podcast on all platforms, hosted by Aaron Clippinger. Being CEO of multiple companies including the signage industry and the software industry, Aaron has over 20 years of consulting and business management. His software has grown internationally and with over a billion dollars annually going through the software. Using his Accounting degree, Aaron will be talking about his organizational ways to get things done. Hi ...
…
continue reading
As She Rises brings together local poets and activists from throughout North America to depict the effects of climate change on their home and their people. Each episode carries the listener to a new place through a collection of voices, local recordings and soundscapes. Stories span from the Louisiana Bayou, to the tundras of Alaska to the drying bed of the Colorado River. Centering the voices of native women and women of color, As She Rises personalizes the elusive magnitude of climate cha ...
…
continue reading
Ever wondered what makes great go-to-market leaders grow, even when the going gets tough? We have, too. And we’re on a mission to uncover the magic that makes that growth happen. This is Go-to-Market Magic, the show where we talk to go-to-market leaders and visionaries about the “aha!” moments they experience and the pivotal decisions they’ve made, all in the name of growth. And we’re not just talking about revenue growth that goes up and to the right — we’ll also discuss how they improve th ...
…
continue reading
The Partnership Economy explores the power of partnerships through candid conversations and stories with industry leaders. Our hosts, David A. Yovanno, CEO and Todd Crawford, Co-founder, of impact.com, unpack the future of partnerships as a lever for scale and an opportunity to put the consumer first.
…
continue reading
Bitcoin groundbreakers share personal stories of how Bitcoin is changing lives for the better. Host Mauricio Di Bartolomeo, co-founder and CSO of Ledn, speaks with leading Bitcoin voices, entrepreneurs, and human rights advocates to hear their unique journey and practical real-world examples of how Bitcoin has made a positive impact in their lives. Brought to you by Ledn, a leading financial services company built for Bitcoin & digital assets. Ledn offers a suite of lending, saving and tradi ...
…
continue reading
Welcome to the What’s Next! Podcast. I’ve met so many brilliant people as I traveled the globe and have had some fascinating conversations that I’ve wished had been recorded so I could share them with you - this podcast was a way for me to recreate those moments and let you in on some fantastic insights. My current conversations center around one objective: what's next for companies and individuals as they look to innovate and grow. I hope these conversations inspire you as much as they have ...
…
continue reading
Tim Harford and the More or Less team try to make sense of the statistics which surround us. From BBC Radio 4
…
continue reading
How do I start an online business? How do I build a brand online? How do I get traffic and attention to my online business? The biggest question is, can I start a business online and replace my current JOB? Welcome to The Rock Your Brand podcast show where we answer ALL of these questions and a ton MORE! Scott Voelker, the host will share with you everything you need to know and help you to build a Future Proof Business that will allow you the ultimate Freedom. Scott shares tips and strategi ...
…
continue reading
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Player FM - приложение для подкастов
Работайте офлайн с приложением Player FM !
Работайте офлайн с приложением Player FM !



